|
I am currently a research scientist at Meta. I have graduated from the department of Computer Science at University of Maryland, College Park, advised by Prof. Abhinav Shrivastava. I obtained my Bachelor's degree at University of Chinese Academy of Sciences, China. My research interests lie primarily in multimodal learning and reasoning for video, with a specific focus on video-language models, generative video, and neural representation learning. My work spans a diverse range of tasks, including long-term video understanding, action recognition and localization, summarization, compression, and generation. Ultimately, I aim to build video foundation models that can perceive, reason, and create with human-level understanding. Email: bohe [at] umd [dot] edu CV / Github / Google Scholar / LinkedIn |

|
|
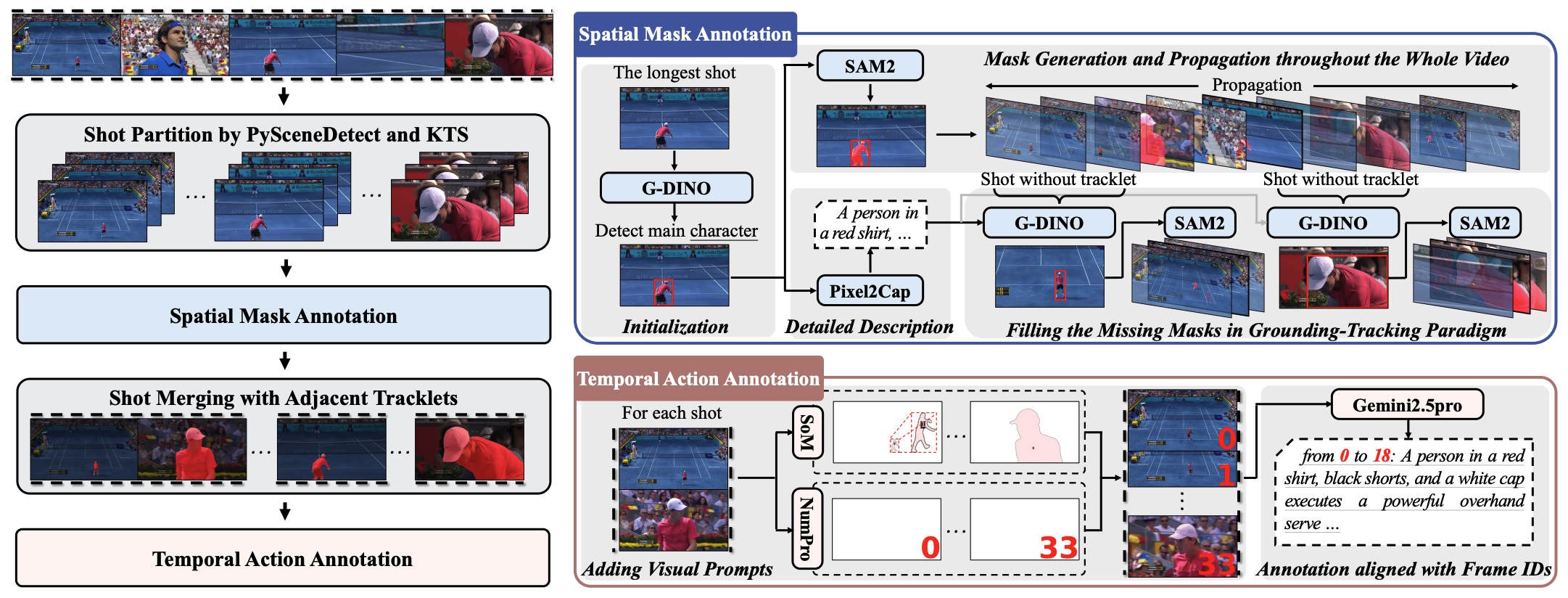
VideoLoom: A Video Large Language Model for Joint Spatial-Temporal Understanding
Jiapeng Shi, Junke Wang, Zuyao You, Bo He, Zuxuan Wu Under Submission arxiv / code We introduces VideoLoom, a unified Video LLM for joint spatial–temporal understanding, supported by LoomData-8.7k, a human-centric dataset with fine-grained temporal and spatial annotations. VideoLoom achieves state-of-the-art or competitive results across multiple benchmarks. |

|
Pix2Cap-COCO: Advancing Visual Comprehension via Pixel-Level Captioning
Zuyao You, Junke Wang, Lingyu Kong, Bo He, Zuxuan Wu Under Submission arxiv / code We introduce Pix2Cap-COCO, the first panoptic pixel-level caption dataset for fine-grained visual understanding, featuring 167,254 pixel-aligned, instance-specific captions generated automated annotation pipeline, and propose a new task—panoptic segmentation-captioning. |
|
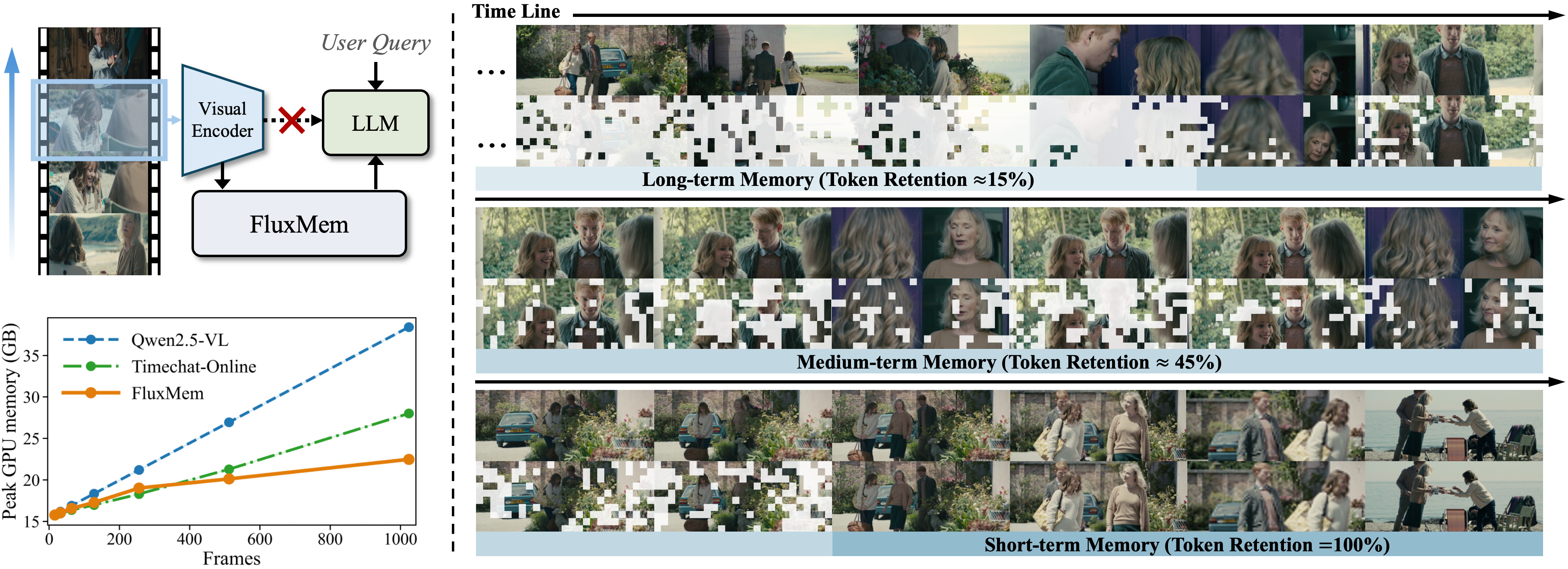
FluxMem: Adaptive Hierarchical Memory for Streaming Video Understanding
Yiweng Xie, Bo He, Junke Wang, Xiangyu Zheng, Ziyi Ye, Zuxuan Wu CVPR, 2026 project page / arxiv / code We introduce FluxMem, a training-free framework for efficient streaming video understanding that adaptively compresses redundant visual tokens via temporal and spatial consolidation guided by scene dynamics. FluxMem achieves state-of-the-art performance on online benchmarks while preserving strong offline accuracy with up to 65% fewer visual tokens. |
|
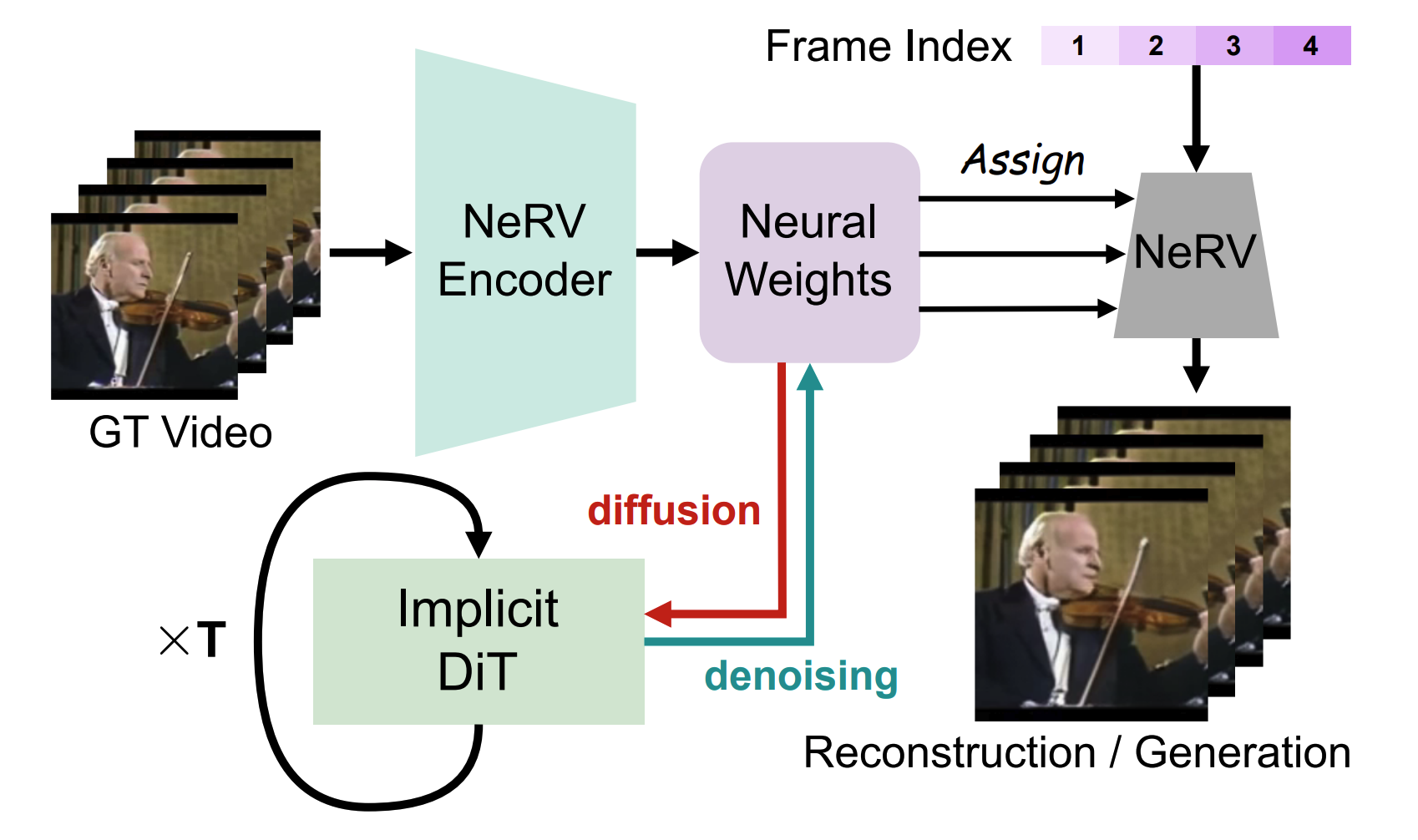
NeRV-Diffusion: Diffuse Implicit Neural Representation for Video Synthesis
Yixuan Ren, Hanyu Wang, Hao Chen, Bo He, Abhinav Shrivastava ICLR, 2026 project page / arxiv Generate network weights via a diffusion model, which parameterize an implicit neural representation and self-decode to synthesize a video. |
|
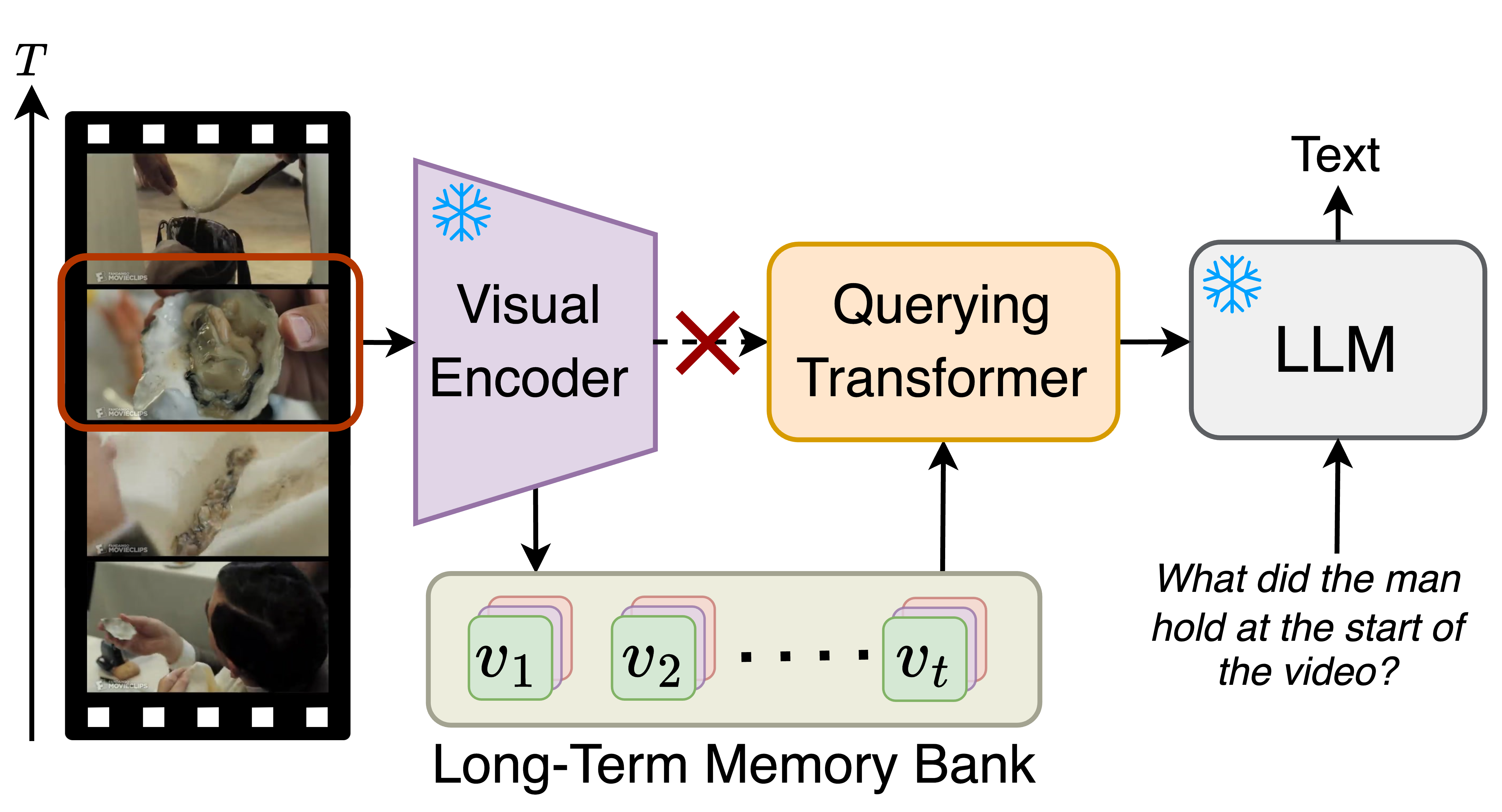
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Abhinav Shrivastava, Ser-Nam Lim CVPR, 2024 project page / arxiv / code We propose a memory-augmented large multimodal model for efficient and effective long-term video understanding ability. Our model can achieve state-of-the-art performances across multiple tasks such as long-video understanding, video question answering, and video captioning. |
|
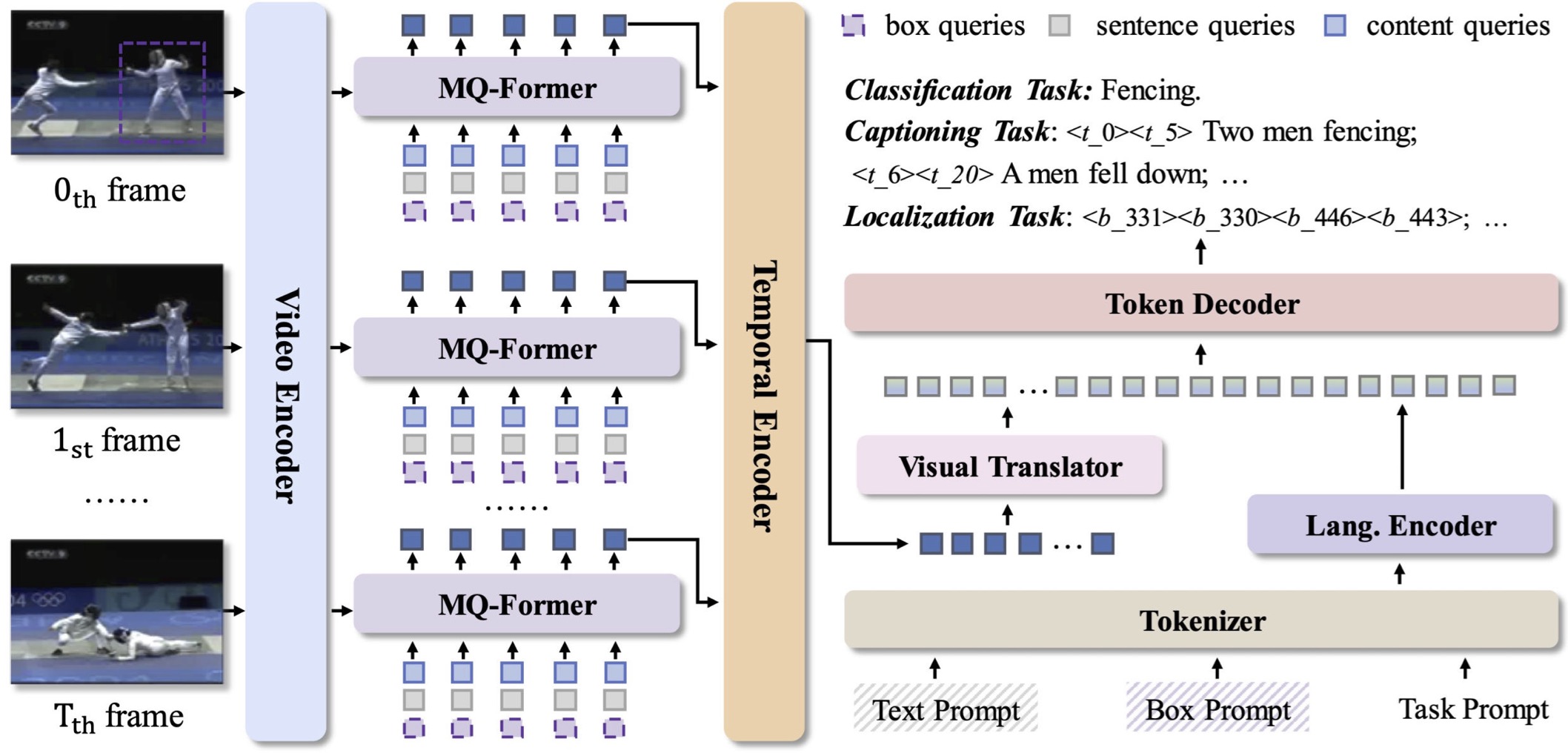
Junke Wang, Dongdong Chen, Chong Luo, Bo He, Lu Yuan, Zuxuan Wu, Yu-Gang Jiang CVPR, 2024 arxiv / code We seek to unify the output space of video understanding tasks by using languages as labels and additionally introducing time and box tokens. This enables us to address various types of video tasks, including classification (such as action recognition), captioning (covering clip captioning, video question answering, and dense video captioning), and localization tasks (such as visual object tracking) within a fully shared encoder-decoder architecture, following a generative framework. |

|
Yixuan Ren, Jing Shi†, Zhifei Zhang†, Yifei Fan, Zhe Lin, Bo He, Abhinav Shrivastava WACV, 2024 paper Edit the color tone of an image with the editing styles spatially adaptive to its content.. |
|
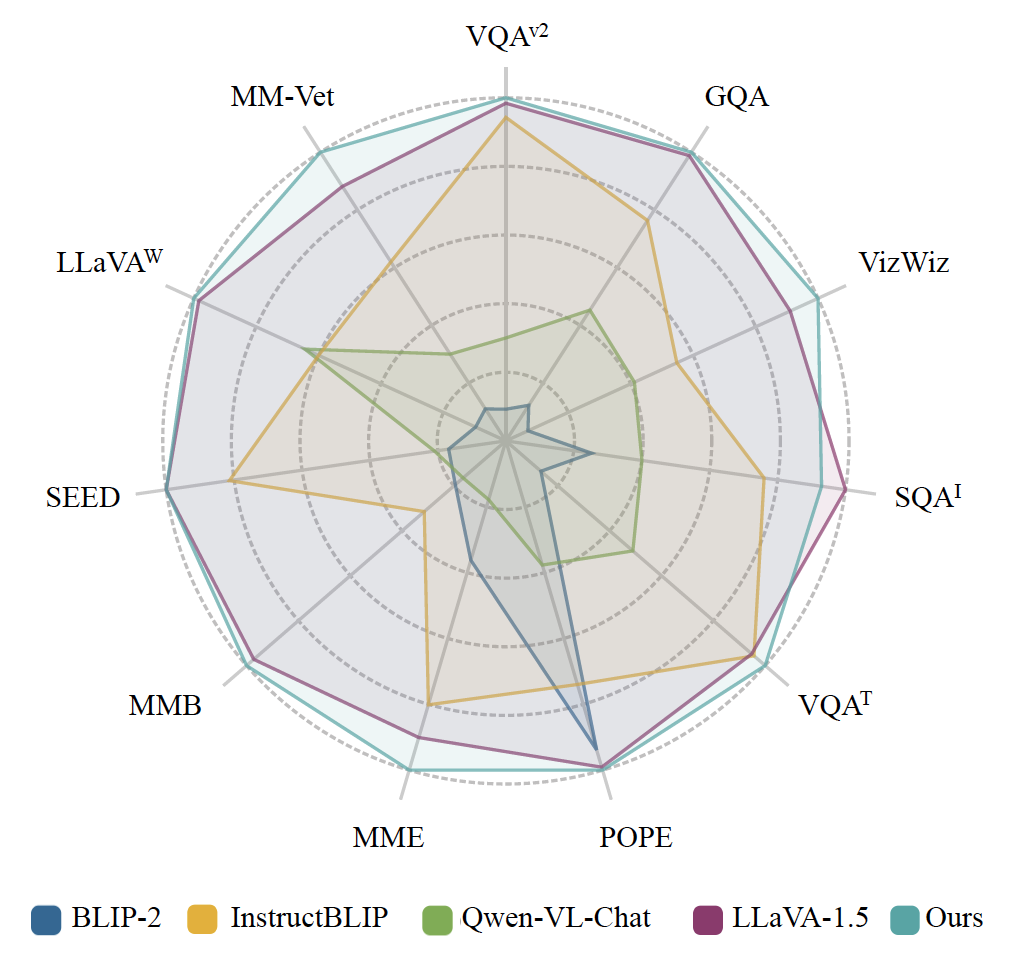
Junke Wang, Lingchen Meng, Zejia Weng, Bo He, Zuxuan Wu, Yu-Gang Jiang arXiv arxiv / code We introduce a fine-grained visual instruction dataset, LVIS-Instruct4V, which contains 220K visually aligned and context-aware instructions produced by prompting the powerful GPT-4V with images from LVIS. Notably, by simply replacing the LLaVA-Instruct with our LVIS-Instruct4V, we achieve better results than LLaVA on most challenging LMM benchmarks. |
|
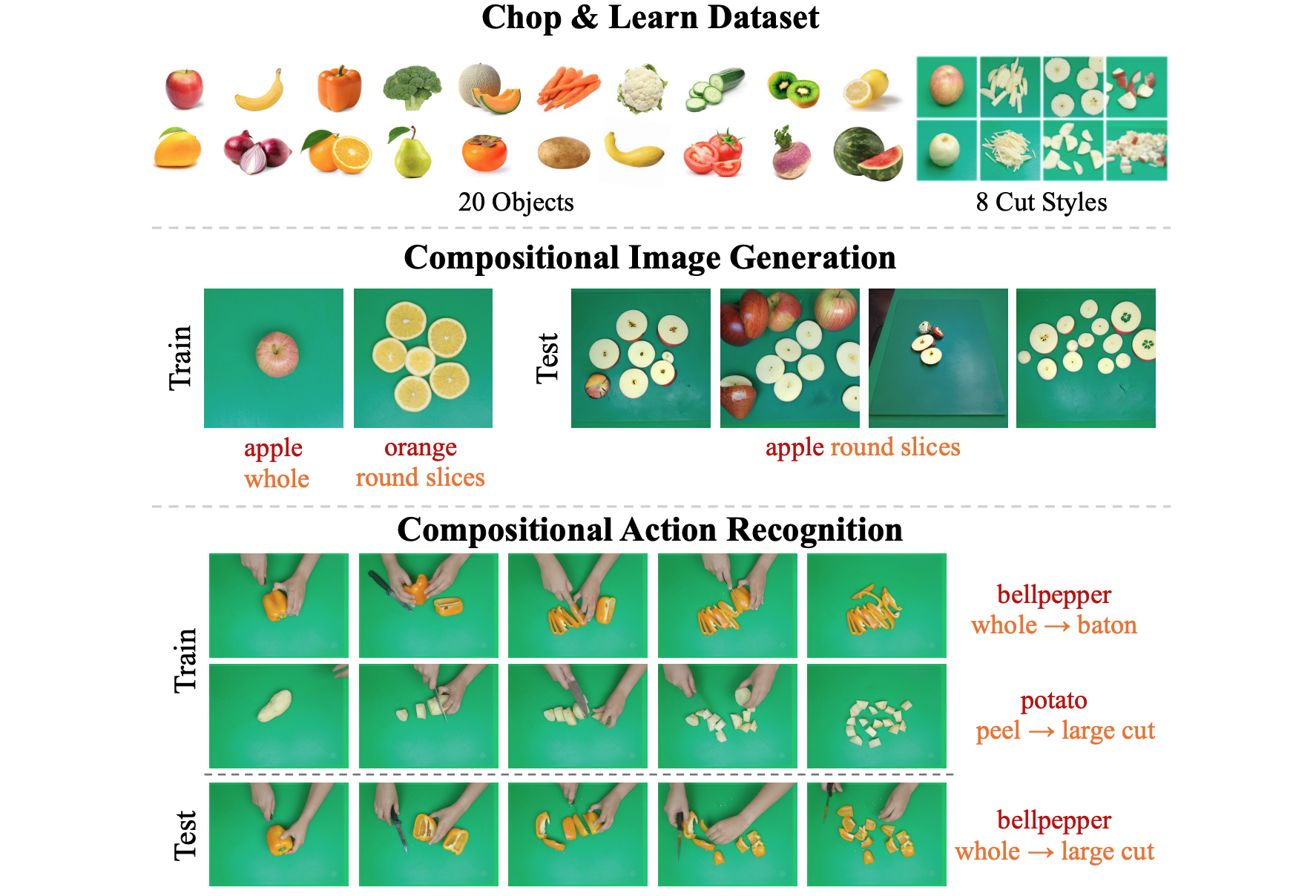
Nirat Saini*, Hanyu Wang*, Archana Swaminathan, Vinoj Jayasundara, Kamal Gupta, Bo He, Abhinav Shrivastava ICCV, 2023 project page / arxiv / code We focus the task of cutting objects in different styles and the resulting object state changes. We propose a new benchmark suite Chop & Learn, to accommodate the needs of learning objects and different cut styles using multiple viewpoints. |
|
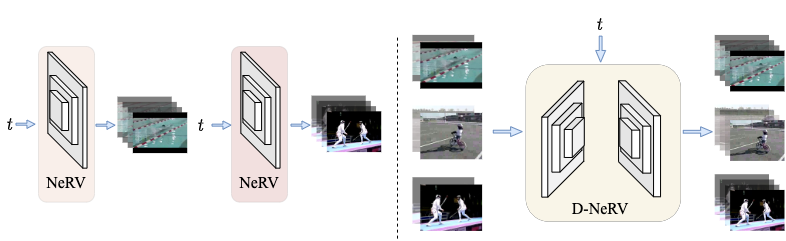
Bo He, Xitong Yang, Hanyu Wang, Zuxuan Wu, Hao Chen, Shuaiyi Huang, Yixuan Ren, Ser-Nam Lim, Abhinav Shrivastava CVPR, 2023 project page / arxiv / code We propose D-NeRV, a novel implicit neural representation based framework designed to encode large-scale and diverse videos. It achieves state-of-the-art performances on video compression. |
|
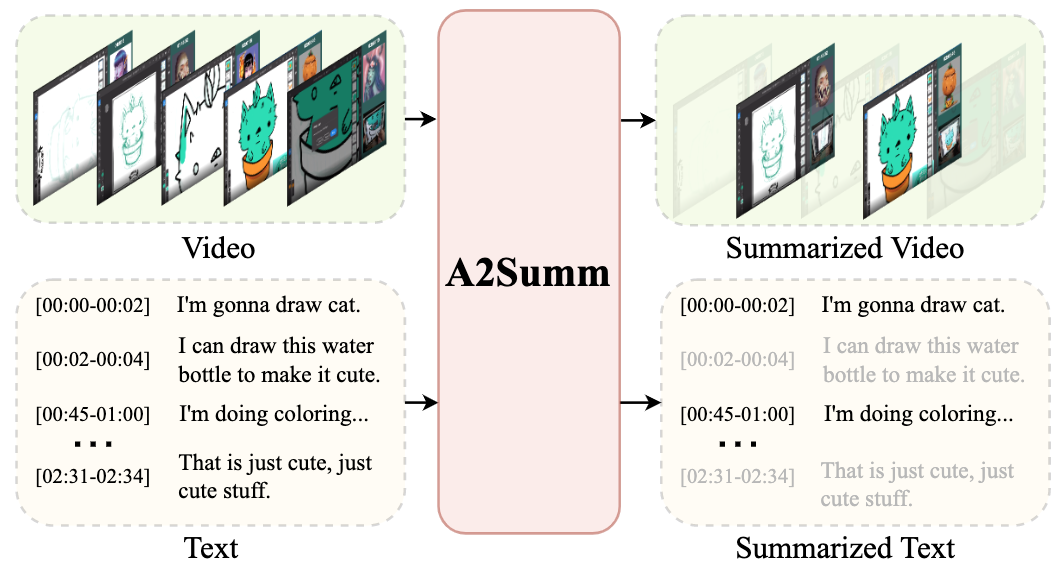
Bo He, Jun Wang, Jielin Qiu, Trung Bui, Abhinav Shrivastava, Zhaowen Wang CVPR, 2023 project page / arxiv / code We propose A2Summ, a novel supervised multimodal summarization framework that summarize video frames and text sentences with time correspondence. We also collect a large-scale multimodal summarization dataset BLiSS, which contains livestream videos and transcribed texts with annotated summaries. |
|
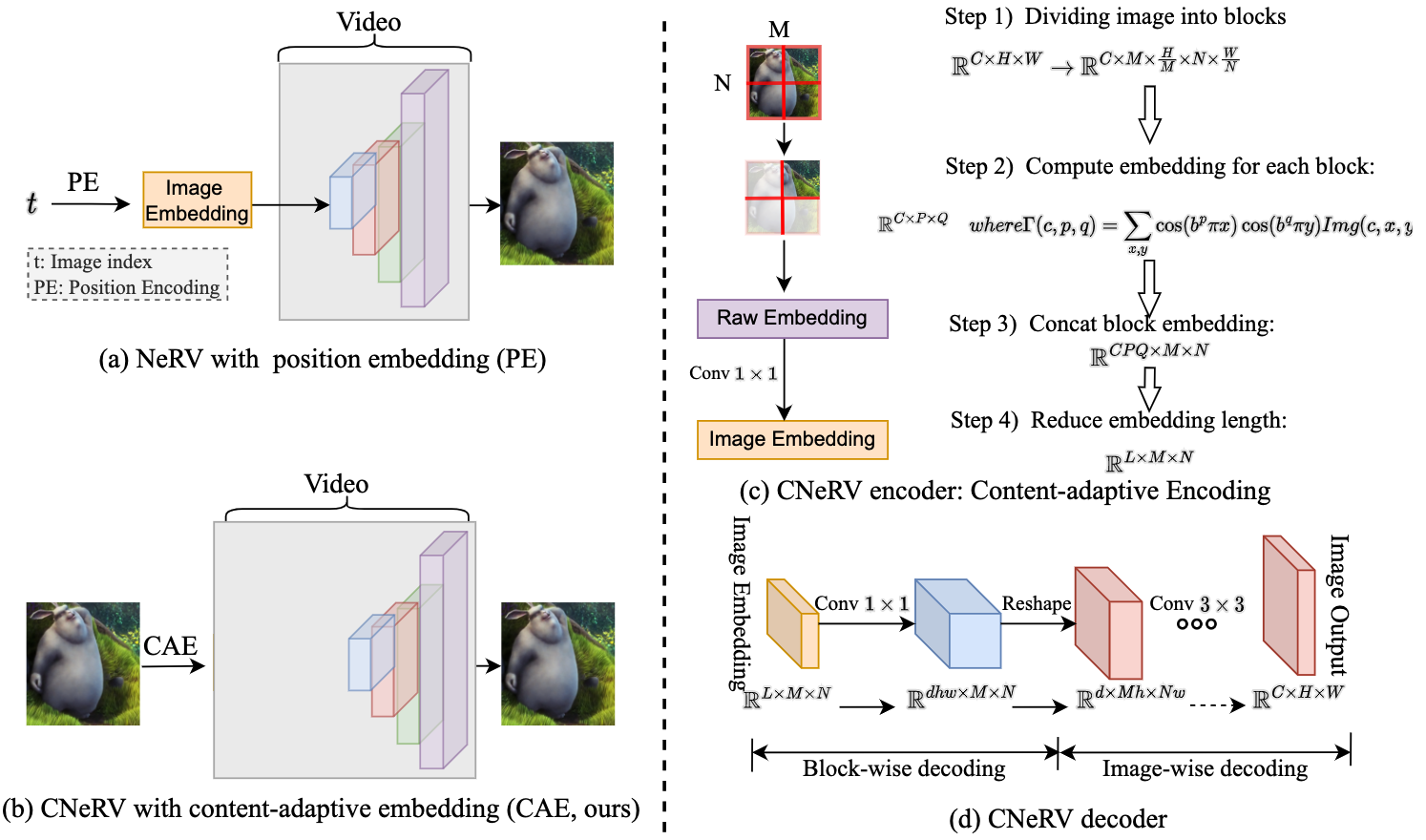
Hao Chen, Matt Gwilliam, Bo He, Ser-Nam Lim, Abhinav Shrivastava BMVC, 2022 (oral) project page / arxiv We propose neural visual representation with content-adaptive embedding, which combines the generalizability of autoencoders with the simplicity and compactness of implicit representation. We match the performance of NeRV, a state-of-the-art implicit neural representation, on the reconstruction task for frames seen during training while far surpassing for unseen frames that are skipped during training. |
|
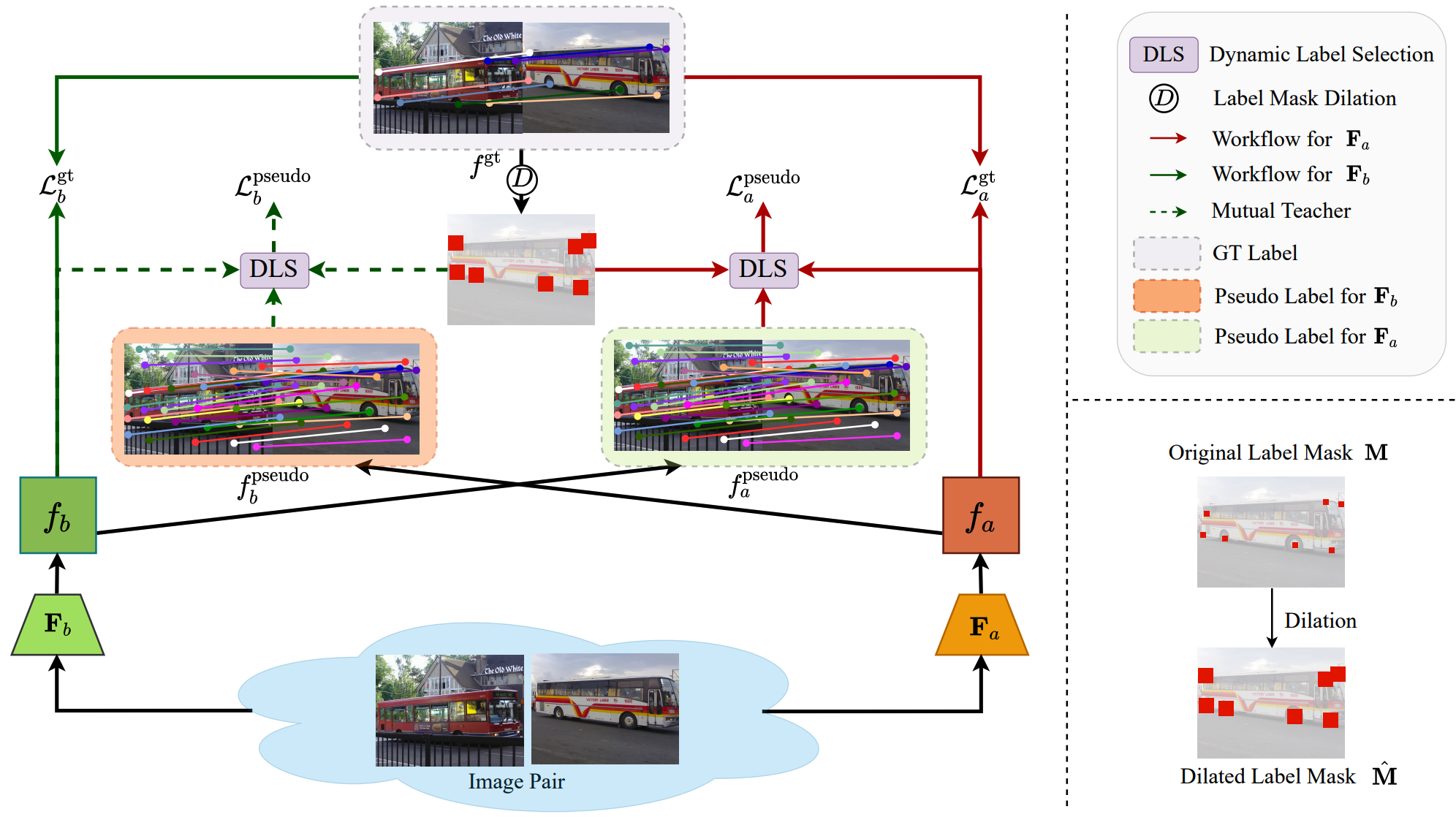
Shuaiyi Huang, Luyu Yang, Bo He, Songyang Zhang, Xuming He, Abhinav Shrivastava ECCV, 2022 project page / arxiv / code We address the challenge of label sparsity in semantic correspondence by enriching supervision signals from sparse keypoint annotations. We first propose a teacher-student learning paradigm for generating dense pseudo-labels and then develop two novel strategies for denoising pseudo-labels. Our approach establishes the new state-of-the-art on three challenging benchmarks for semantic correspondence. |
|
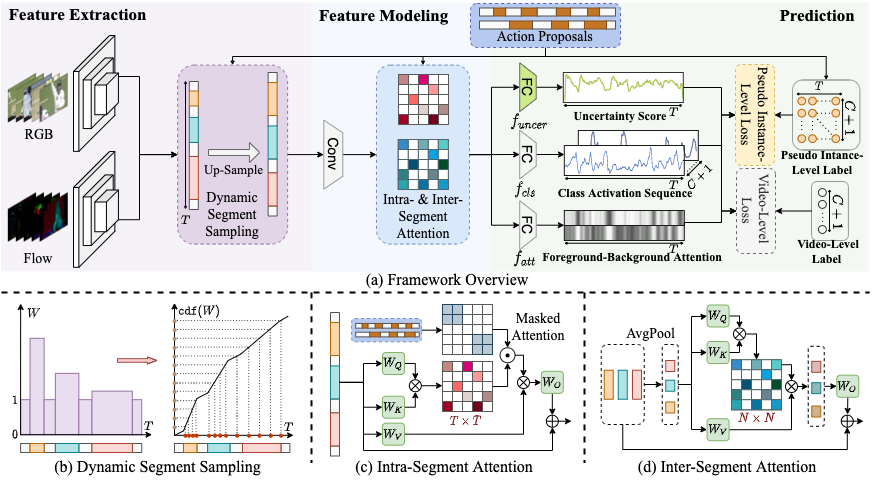
Bo He, Xitong Yang, Le Kang, Zhiyu Cheng, Xin Zhou, Abhinav Shrivastava CVPR, 2022 project page / arxiv / code We propose ASM-Loc, a novel weakly supervised temporal action localization framework that enables explicit, action-aware segment modeling beyond standard MIL-based methods. We establish new state of the art on THUMOS-14 and ActivityNet-v1.3 datasets. |
|
Nirat Saini, Bo He, Gaurav Shrivastava, Sai Saketh Rambhatla, Abhinav Shrivastava ICLR Workshop, 2022 arxiv We propose a computational framework that uses only two object states, start and end, and learns to recognize the underlying actions. |
|
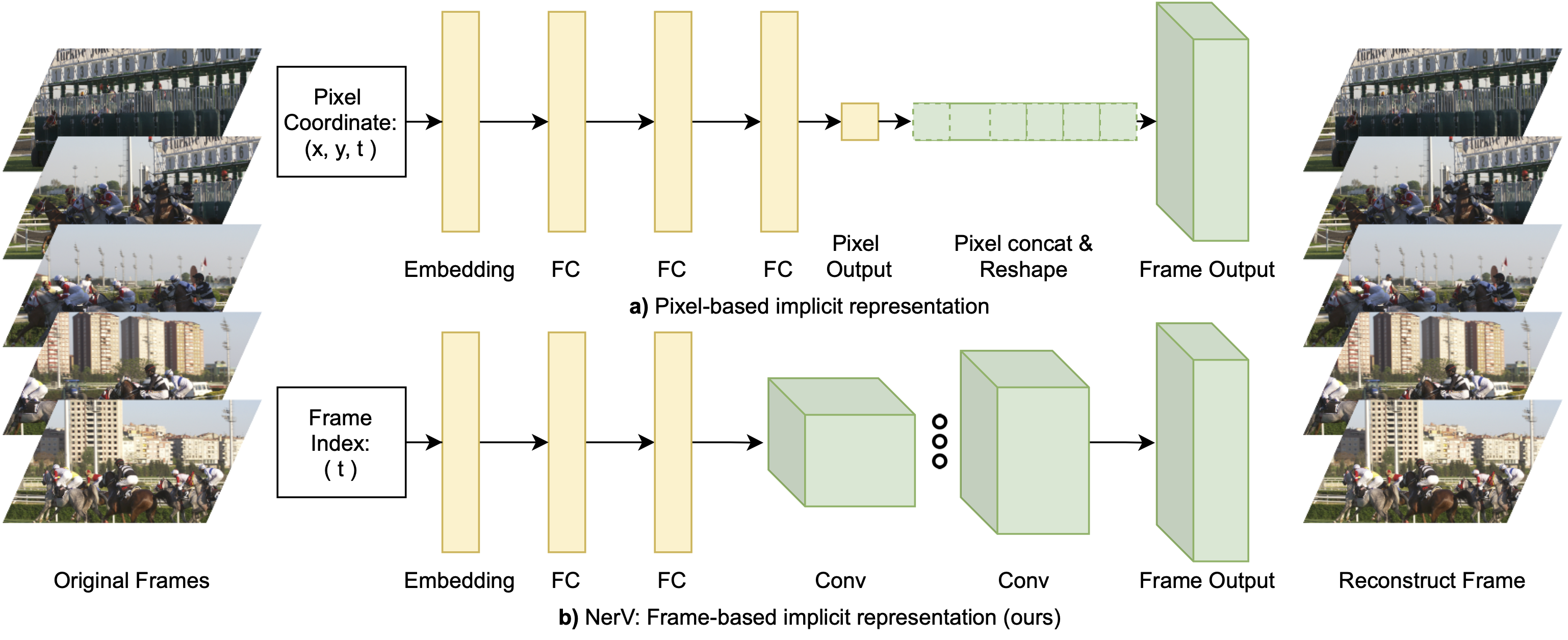
Hao Chen, Bo He, Hanyu Wang, Yixuan Ren, Ser-Nam Lim, Abhinav Shrivastava NeurIPS , 2021 project page / arxiv / code We propose a novel image-wise neural representation (NeRV) to encodes videos in neural networks, which takes frame index as input and outputs the corresponding RGB image. Compared to image-wise neural representation, NeRV imrpoves encoding speed by 25× to 70×, decoding speed by 38× to 132×. And it also shows comparable preformance for visual compression and denoising task. |
|
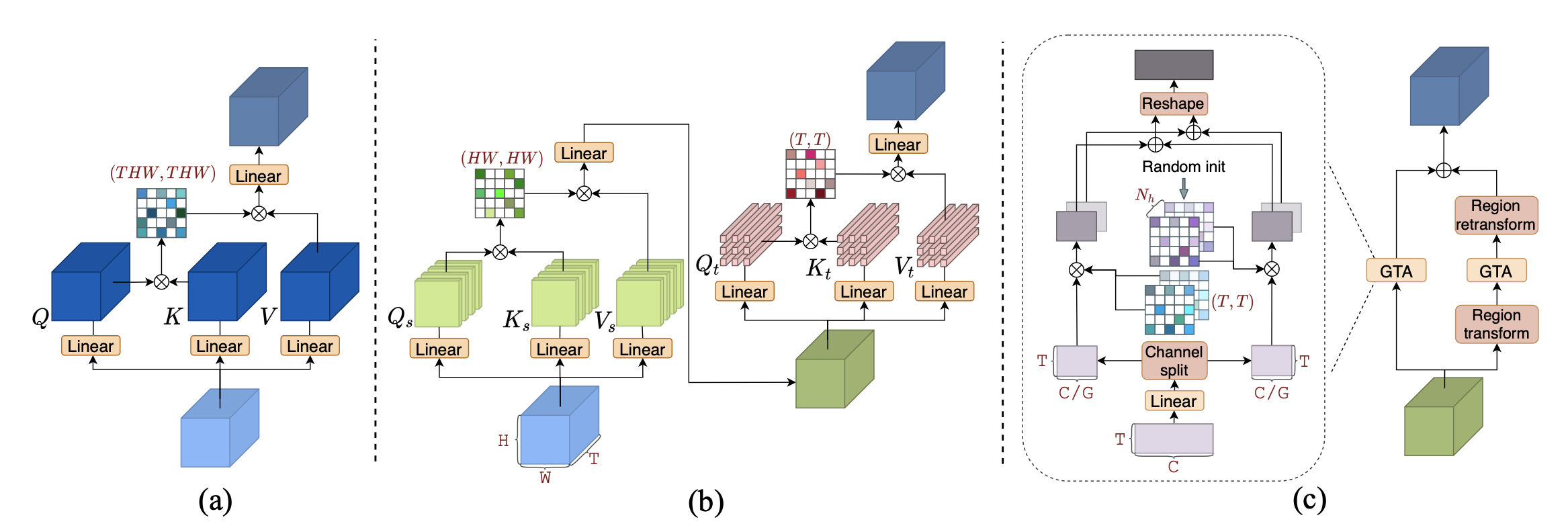
Bo He, Xitong Yang, Zuxuan Wu, Hao Chen, Ser-Nam Lim, Abhinav Shrivastava BMVC , 2021 arxiv We introduce Global Temporal Attention (GTA), which performs global temporal attention on top of spatial attention in a decoupled manner. We apply GTA on both pixels and semantically similar regions to capture temporal relationships at different levels of spatial granularity. |
|
|
Thank Dr. Jon Barron for sharing the source code of his personal page. |